Chapter 8 | The Eyes of Spatial Intelligence: Fusing Vision and Radar

Prologue: Why Humans Perceive a Three-Dimensional World

When you reach out to pick up a glass of water,
your eyes don’t simply “see” a flat, two-dimensional image.
Your brain automatically calculates distance, angle, and depth—
because you have two eyes.
The “parallax” between your two eyes
allows you to perceive three-dimensional space from flat images.
For machines to acquire this same capability, they must combine vision (Camera) and radar (Radar/LiDAR). These are the two “eyes” of spatial intelligence— one sees the detail of the world, the other measures its distances.

1. Vision and Radar: Two Ways of Seeing the World
The difference between vision and radar is like the difference between a photographer and a surveyor.
Visual sensors (Camera) capture the color and texture of the world. They can recognize shapes, edges, text, and symbols. Their strengths are information richness, high resolution, and low cost. But their weaknesses are equally apparent: changes in lighting, glare, fog, rain, and darkness can all render them effectively blind.
Radar sensors (especially LiDAR) use laser pulses to “touch” the world. They are indifferent to color—only distance matters. They can detect the “shape” of objects in darkness, rain, and fog, but their resolution is limited and they cannot discern fine “detail.”
A truly intelligent system must therefore make them work together—
letting vision answer “what is it,”
and letting radar answer “how far away is it.”
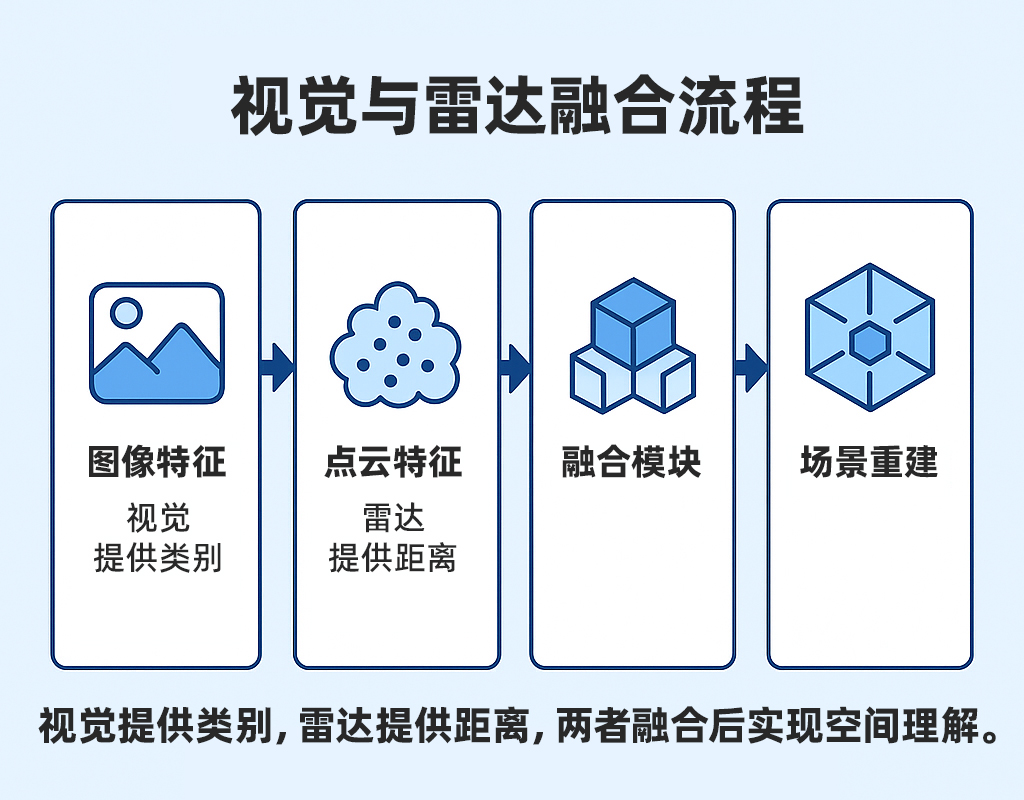
2. From Perception to Understanding: Fusing the Data
Within the multi-source fusion framework of the REVENTADOR platform,
vision and radar are not simply stacked on top of each other.
Through a series of spatiotemporal alignment, feature matching, and filtering algorithms,
they achieve the leap from “seeing” to “understanding.”
- Spatiotemporal Synchronization: The sampling frequencies, exposure moments, and timestamps of the camera and radar must be unified; otherwise, the same target may appear at different positions in each data stream.
- Coordinate Calibration: The coordinate frames of both sensors must be precisely aligned to ensure that image pixels and radar point clouds correspond to the same physical point in space.
- Feature Fusion: Vision provides object classification (e.g., pedestrians, vehicles, road signs), while radar provides precise three-dimensional spatial position. Once fused, the system not only “sees objects” but also understands their “spatial relationships” to one another.
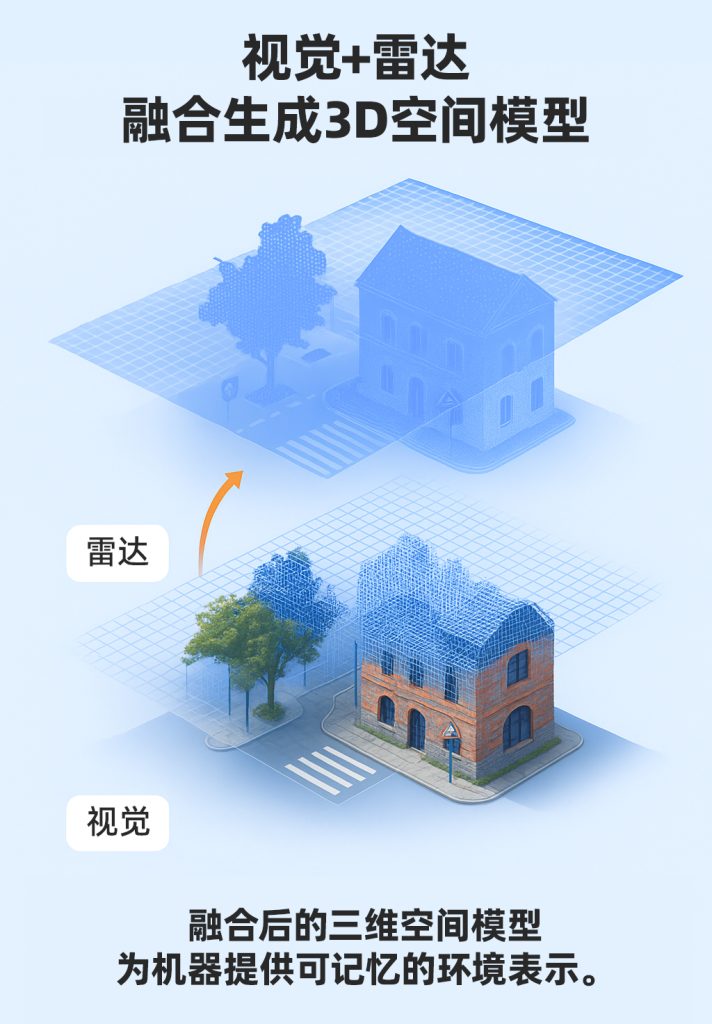
3. The Reliability Advantage of Radar
In urban environments,
varying lighting conditions, rain, fog, and darkness all cause visual sensors to perform inconsistently.
Radar, however, does not rely on visible light.
Its active emission mechanism allows it to operate reliably under any conditions.
This is precisely the “reliability-first” principle that MCT emphasizes in system design. Radar provides a stable perceptual foundation, while vision serves as the high-fidelity refinement layer.
Only by combining both can a spatial intelligence system truly “see” across all environments.
Radar is “certain.” Vision is “rich.” A truly intelligent system must both see clearly and measure accurately.

4. From Fusion to Modeling: The Machine’s “Spatial Memory”
Fusion is not merely cooperation at the perception layer— it is the starting point for spatial modeling.
The data produced by fusing vision and radar
can be transformed by the REVENTADOR platform into a computable three-dimensional Point Cloud Map.
This map not only records geometry, but also retains temporal information,
giving the system genuine “spatial memory.”
In autonomous driving, this means:
a vehicle can recognize intersections it has previously passed through,
understand the spatial relationship between buildings and road surfaces,
and even predict regions that have not been directly observed.
In the fields of embodied intelligence and robotics,
this means machines can localize and navigate autonomously in unfamiliar environments
and optimize their paths based on historical experience.
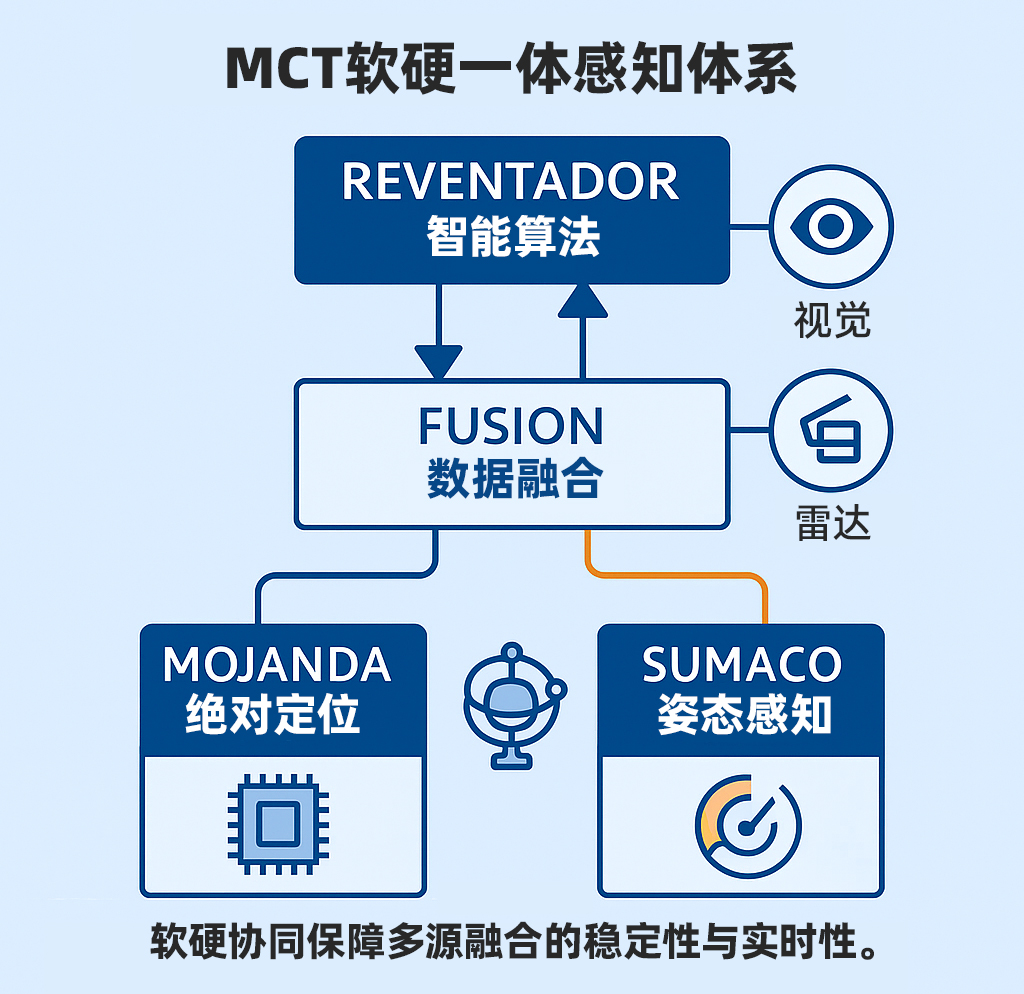
5. An Integrated Hardware-Software Fusion Architecture
MCT’s system is not a “sensor-stacking” approach to perception.
The fusion of vision and radar is the result of deep hardware-software co-design:
- The MOJANDA chip provides a unified clock and high-precision synchronization mechanism;
- SUMACO supplies attitude data to enable dynamic calibration compensation;
- REVENTADOR handles feature matching and multi-source filtering.
This means vision and radar are no longer “parallel modules,”
but components of a unified spatiotemporal perception system.
This integrated hardware-software fusion architecture
allows machines to maintain a reliable understanding of the world even in complex spatial environments.
Perception is no longer just an input— it is the process of understanding the world.
6. Reflections and the Road Ahead
Vision lets machines see the world.
Radar lets machines touch it.
But true intelligence emerges from the dialogue between them.
The spatial intelligence systems of the future
will no longer draw a distinction between “vision” and “radar,”
but will instead possess a unified spatial cognition model—
one that understands the relationships among shape, distance, velocity, and semantics.
When machines can “read space” the way humans do,
they will have achieved true autonomy.
From seeing to understanding— the world of spatial intelligence is being redrawn.
Further Reading
- LiDAR for Autonomous Vehicles, Elsevier, 2021
- Szeliski, Richard. Computer Vision: Algorithms and Applications, 2nd Edition, Springer, 2022
- Paul D. Groves. Principles of Multisensor Navigation and Sensor Fusion, Artech House, 2021
About MCT
MCT (毫厘智能) is an innovation company focused on attitude sensing and absolute positioning for the era of Physical AI. With artificial intelligence at our core, we pursue a “data-driven, hardware-software integrated” strategy to develop and deliver comprehensive attitude sensing and absolute positioning solutions across hardware and software. We serve the fields of embodied intelligence, urban assisted driving, low-altitude economy, robotics, and intelligent devices. Building on our proprietary automotive-grade BeiDou high-precision chips and modules, and integrating high-precision IMU, vision, and radar sensor technologies with large-scale datasets, MCT provides more reliable, safer, and more accurate technical support for autonomous planning and automatic control—continuously advancing the spatial perception capabilities of intelligent platforms.
Want to learn more about MCT’s latest developments? Visit www.mctech.ai / www.mctai.cn, or follow our WeChat Official Account: 「毫厘智能 MCT」.